ビッグデータに幻滅する時がやってきた!?(英文)
Last year was a year when the phrase “Big Data” was all over the place. Dig through the troves of data your business generates, the thinking goes, and some useful business intelligence falls out. That, at least, is the idea, and there are numerous companies — some startups, some big and established players — trying to build business plans on different aspects of that idea.
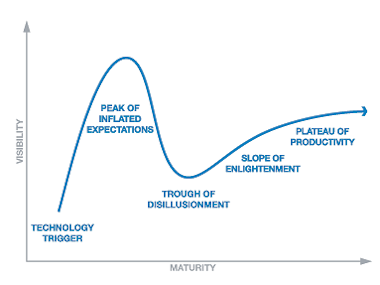
But in the course of being reduced to a simple buzzy phrase, Big Data as a concept implies some expectations, some realistic, some undoubtedly not. The research house Gartner has a phrase for this tendency as well: The Hype Cycle.
The Hype Cycle goes like this: A new technology that promises to fundamentally “change everything” gets talked up incessantly in the press and at industry events and often also in research reports. At some point the chatter peaks, and expectations reach a fever pitch. Soon, maybe a year or two after it all started to build and some money has been spent and everything that was supposed to have changed for the better actually hasn’t, the narrative focus turns negative. What seemed so brilliant and earthshaking 18 months ago, seems in restrospect to have been an ill-advised waste of time, money and attention.
This is what Gartner calls the “Trough of Disillusionment” phase of the Hype Cycle.
Gartner analyst Svetlana Sicular argues in a blog post that Big Data may have reached that point. She has been “hearing from people in the center of the Hadoop movement,” the open-source technology central to companies like Cloudera, Hortonworks and MapR. She also presents a video of a Hadoop gathering called Elephant Riders where reps from these three companies are debating its current state. (It’s about 90 minutes and if you’re so inclined, you can see it here.)
By Gartner’s standards, the trough of disillusionment may indeed have arrived, though you certainly wouldn’t be able to tell from the level of investment interest in companies like Cloudera, which late last year raised a massive $65 million round of funding.
One source of that disillusionment, she writes, is that companies are struggling with a basic problem: What questions do you attempt to answer with your data in the first place? “Several days ago, a financial industry client told me that framing a right question to express a game-changing idea is extremely challenging,” Sicular wrote. “First, selecting a question from multiple candidates; second, breaking it down to many sub-questions; and, third, answering even one of them reliably. It is hard.”
Hadoop doesn’t exactly make that process any easier. Once you’ve decided to use it, getting anything useful out of it requires some pretty specialized knowledge and training, and finding the right people to do that isn’t easy. But the industry is beginning to respond to that need: Startups like Mortar Data have sought to make Hadoop more readily accessible to mainstream programmers, while another called Trifacta makes the resulting data easier to manipulate.
And versions of Hadoop itself are getting incrementally easier to work with. Hortonworks, for example, recently released HDP 1.2, a new version of the open-source platform, but also Sandbox, a set of training tools that lets developers play around with Hadoop and get a feel for its use.
I talked with Hortonworks CEO Rob Bearden recently, and he said that, in 2011, companies had no idea what Hadoop could be used for, then spent 2012 experimenting with it, and now want to get some real-world value out of it in 2013. “This year, all the technology is coming together in a way that is consumable,” he said. “In the last quarter of last year we saw a lot of interesting production environments. Now the objectives are becoming clear for getting useful in 2013.”
The next milestone in the Hype Cycle, Sicular writes, is negative press. Eventually it’s followed by a period called the “Slope of Enlightenment,” and finally the “Plateau of Productivity.” It’s nice to know there could be a positive conclusion to all this somewhere down the road.
from:
http://allthingsd.com/20130124/has-big-data-reached-its-moment-of-disillusionment/









